Материалы по тегу: sapphire rapids
|
05.05.2023 [13:16], Сергей Карасёв
Supermicro представила первые коммерческие серверы на базе ускорителей Intel MaxКомпания Supermicro анонсировала стоечные системы SYS-421GE-TNRT и SYS-821PV-TNR — первые в отрасли коммерческие серверы, оборудованные ускорителями Intel Max (Ponte Vecchio). Аппаратной основой представленных решений служат процессоры Intel Xeon Sapphire Rapids. Обе новинки рассчитаны на установку двух чипов в исполнении Socket E (LGA-4677). Поддерживается до 8 Тбайт оперативной памяти DDR5-4800 в виде 32 модулей ёмкостью 256 Гбайт каждый. Есть 24 отсека во фронтальной части для SFF-накопителей U.2/SATA/SAS. Модель SYS-421GE-TNRT допускает установку восьми ускорителей Data Center GPU Max 1100 с 48 Гбайт памяти HBM2 каждый. Кроме того, предусмотрены два коннектора для M.2 NVMe SSD. Система оборудована двумя сетевыми портами 10GbE (Intel X710-AT2), выделенным сетевым портом управления, разъёмом D-Sub и последовательным портом. 
Источник изображений: Supermicro Для CPU может применяться воздушное или жидкостное охлаждение. Сервер наделён восемью вентиляторами повышенной надёжности. Устройство выполнено в форм-факторе 4U. Питание обеспечивают четыре блока мощностью 2700 Вт стандарта 80 PLUS Titanium. Диапазон рабочих температур — от +10 до +35 °C. 
Сервер SYS-821PV-TNR, в свою очередь, может нести на борту до восьми ускорителей Data Center GPU Max 1550 OAM со 128 Гбайт памяти HBM2 каждый. Для CPU и GPU может быть задействовано воздушное или жидкостное охлаждение. Заявленная производительность достигает 6,7 Пфлопс FP16/BF16. Другие характеристики будут раскрыты позднее.
25.04.2023 [20:01], Алексей Степин
Как Aurora, но поменьше: запущен тренировочный суперкомпьютер Sunspot на чипах Intel MaxОдин из самых масштабных проектов в области высокопроизводительных вычислений (HPC), 2-Эфлопс суперкомпьютер Aurora, который планирует вскоре ввести в строй Аргоннская национальная лаборатория (ANL), получил ещё одну тестовую платформу. Новый мини-кластер Sunspot, включающий в себя две стойки будущей машины, является прекрасным полигоном для отладки ПО. Aurora будет состоять из более чем 10 тыс. вычислительных узлов, а Sunspot включает в себя 128 узлов, каждый из которых, впрочем, имеет весьма серьёзную конфигурацию. На борту такой узел несёт пару процессоров Intel Xeon Max (Sapphire Rapids + 64 Гбайт HBM2e), а также шесть ускорителей Intel Max Series (Ponte Vecchio). Sunspot использует в качестве интерконнекта фирменную сеть HPE/Cray Slingshot последнего поколения. 
Источник: Argonne Leadership Computing Facility Как считает глава Argonne Leadership Computing Facility (ALCF), полная идентичность архитектур позволит разработчикам оптимизировать код для максимального использования всех возможностей Sapphire Rapids и Ponte Vecchio. Ранее тестовыми платформами служили кластеры Iris, Arcticus, Florentia самой Аргоннской лаборатории, а также Borealis, принадлежащий Intel. Система Sunspot была запущена ещё в декабре, с тех пор к ней получили доступ более 180 исследователей из 20 команд разработчиков в рамках программ Aurora Early Science Program (ESP) и Exascale Computing Project (ECP). 
Процесс сборки Aurora идёт полным ходом Отмечается, что достигнутые на «железе» Intel Max результаты внушают оптимизм. В ряде научно-технических задач прирост производительности от перехода на ускорители Intel составил от 20 до 70 %, а в разрабатываемом аргоннцами Hardware/Hybrid Accelerated Cosmology Code выигрыш достиг 2,6 раз. Ожидается, что дальнейшая более тонкая оптимизация позволит улучшить результаты. Интересно, что даже после запуска Aurora система Sunspot демонтирована не будет, а станет, как и все предыдущие тестовые платформы ALCF, общедоступным «полигоном для новичков».
28.02.2023 [00:08], Игорь Осколков
Xeon EE для 5G: Intel представила процессоры Sapphire Rapids со встроенным ускорителем vRAN BoostНа MWC 2023 компания Intel, как и обещала когда-то, представила специализированное решение для ускорения внедрения 5G и 4G, которое упрощает развёртывание виртуализированных сетей радиодоступа (vRAN) — процессоры Xeon Sapphire Rapids с интегрированным ускорителем vRAN Boost. Новинки, по словам компании, оптимизированы для сигнальной обработки и обработки пакетов, балансировки, ИИ и машинного обучения, а также динамического управления энергопотреблением.  Новинки позволят телеком-провайдерами консолидировать уже развёрнутые сети 4G/5G, удвоив ёмкость vRAN (по сравнению с Ice Lake-SP), а также вдвое улучшить энергоэффективность обработки L1-трафика в режиме реального времени благодаря расширенным возможностям сбора телеметрии и управления состоянием отдельных ядер (переход в сон и обратно) с низким уровнем задержки, а также гибкого перераспределения сетевых и иных нагрузок между ядрами.  Компания предложит заказчикам две серии Xeon EE (Enhanced Edge) с числом ядер до 20 или до 36 шт. и восемью каналами памяти, DDR5-4000 и DDR5-4400 соответственно. В обоих случаях речь об односокетных платформах. Некоторые модели также имеют поддержку AMX-инструкций и расширенный диапазон рабочих температур. Компанию новинкам составят FPGA Agilex 7, eASIC N5X и сетевые контроллеры E810 (Columbiaville). 
Источник: Intel Xeon EE используют расширения AVX (в частности, AVX512-FP16) для обработки сигналов и аппаратные блоки ускорения vRAN Boost для прямой коррекции ошибок (FEC, Forward Error Correction) и дискретного преобразования Фурье (DFT, Discrete Fourier Transformation), что позволяет снизить энергопотребление на величину до 20 % по сравнению с обычными Sapphire Rapids, поскольку для них и более ранних CPU требуются дискретные ускорители вроде ACC100. Для работы с новыми функциями предлагается DPDK и VPP, а драйверы совместимы с O-RAN ALLIANCE Accelerator Abstraction Layer (AAL) API. Также поддерживается и референсная платформа Intel FlexRAN.  В целом же, Intel продолжает продвигать идею замены специализированного 4G/5G-оборудования на как можно более стандартные серверы, что приводит к снижению совокупной стоимости владения (TCO) и повышает функциональность, гибкость и масштабируемость сетей нового поколения благодаря переходу к программно определяемым решениям. Среди ключевых партнёров компания называет Advantech, Capgemini, Canonical, Dell Technologies, Ericsson, HPE, Mavenir, Quanta Cloud Technology, Rakuten Mobile, Red Hat, SuperMicro, Telefonica, Verizon, VMware, Vodafone и Wind River.  На MWC 2023 также были показаны анонсированные на днях edge-серверы Dell на базе новых Xeon EE. Кроме того, Intel при сотрудничестве с SK Telecom разработала референсную программную платформу Intel Infrastructure Power Manager для ядра 5G-сети, которая позволяет ещё больше снизить (до -30 %) фактическое энергопотребление процессоров. Наконец, компания на пару с Samsung продемонстрировала работу 5G UPF (User Plane Function) на скорости 1 Тбит/с, для чего оказалось достаточно двухсокетного сервера с Sapphire Rapids, который, судя по всему, всё же был снабжён ускорителями.
19.01.2023 [16:55], Алексей Степин
Dell анонсировала серверы PowerEdge на базе процессоров Sapphire RapidsDell, пусть и с некоторым запозданием, представила сразу несколько модельных рядов серверов на базе новых Intel Xeon Sapphire Rapids. В первую очередь обновление затронуло серию Core, которая получила пять новых моделей: компактный одноюнитовый сервер PowerEdge R660, две вариации PowerEdge R760 высотой 2U, одна из которых, R760xa, рассчитана на установку шести ускорителей: четырёх двухслотовых с теплопакетом 300 Вт в передней корзине и двух компактных (TDP 75 Вт) — в задней. В случае использования только однослотовых плат ускорителей их число можно увеличить до 12, так что это одна из самых высокоплотных и при этом компактных платформ для ускорителей. 
Dell PowerEdge R660/R660xs. Источник изображений: StorageReview Модели R760 и R660 с суффиксом xs относятся к сегменту начального уровня, они лишены некоторых опций, реализованных в основной серии. Также в среди новинок есть серверы PowerEdge R960 и R860 высотой 4U и 2U, интересные тем, что это не двух-, а четырёхпроцессорные системы. В своё время Dell пропустила поколение 4S-платформу на базе Cooper Lake-SP, так что в своём классе это долгожданное обновление. 
Dell PowerEdge R760. Источник изображений: StorageReview Модель Dell PowerEdge C6220 представляет собой модульное шасси высотой 2U c четырьмя вычислительными узлами на базе Sapphire Rapids. Она оснащена фирменной «мультивекторной» системой воздушного охлаждения, достаточно эффективной, чтобы позволить экономию на СЖО. 
Модели начального уровня и модульное шасси PowerEdge C6620 с воздушным охлаждением Для гиперскейлеров компания предлагает Dell HS5610 и HS5620 высотой 1 и 2U соответственно. В этих решениях компания воплотила тенденцию облачных провайдеров к отказу от проприетарных решений: система удалённого управления и мониторинга здесь базируется на OpenBMC и Open Server Manager. Есть среди новинок и модель в башенном форм-факторе, PowerEdge T560. Она поддерживает пару Sapphire Rapids c TDP до 250 Вт и может вмещать 12 полноразмерных накопителей 3,5″, либо 24 — в формате 2,5″. Возможна установка двух полноразмерных ускорителей. 
Серверы PowerEdge с поддержкой NVIDIA SXM5 и Intel Ponte Vecchio Наконец, мощные системы серии XE9680/9640/8640 предназначены для машинного обучения и спроектированы с учётом соответствующих требований. Старшая модель поддерживает установку восьми ускорителей NVIDIA H100 (SXM5), либо восьми A100 (SXM4), а младшая XE8640 — четырёх таких ускорителей. PowerEdge XE9640 интересна ориентацией на использование ускорителей Intel Max (Ponte Vecchio) с поддержкой интерконнекта GPU-GPU. Новые серверы Dell имеют ряд любопытных фирменных особенностей, среди которых выделяется BOSS-N1. Это отдельный RAID-контроллер с поддержкой безопасной загрузки UEFI и предназначенный для установки операционной системы. Как указывает литера N, новинка использует накопители NVMe. Дисковая корзина BOSS-N1 доступна с задней панели сервера и поддерживает функцию горячей замены. 
Источник изображений: StorageReview Не забросила Dell и направление аппаратных RAID-контроллеров, представив в этой серии новинку PERC12, которая, если верить заявлениям, вдвое превосходит по производительности решение предыдущего поколения и вчетверо — показатели PERC10. Контроллер поддерживает PCIe 5.0 и все современные интерфейсы: SATA-3, SAS-4 и NVMe. Также анонсирован контроллер H965e для создания JBOD-массивов с поддержкой SAS-4.
11.01.2023 [03:00], Игорь Осколков
Асимметричный ответ: Intel официально представила процессоры Xeon Sapphire RapidsIntel официально представила серверные процессоры Xeon семейства Sapphire Rapids (SPR), выход которых изрядно задержался, а также ускорители ранее известные как Ponte Vecchio и теперь объединённые вместе с HBM-версиями SPR в отдельную HPC-серию Max. В этом поколении Intel не смогла догнать AMD EPYC Genoa по числу ядер, числу каналов памяти и линий PCIe, но заготовила ассиметричный, хотя и очень странно реализованный ответ. Всего представлено 52 модели с числом P-ядер от 8 до 60 и с TDP от 125 до 350 Вт. По числу ядер это существенный апгрейд по сравнению с Ice Lake-SP (до 40 ядер), да и IPC вырос у Golden Cove на 15 % в сравнении с Sunny Cove. Но это существенный проигрыш в сравнении с Genoa (до 96 ядер), особенно если учитывать их максимальный TDP в 360 Вт (cTDP до 400 Вт). Правда, у Sapphire Rapids есть ещё и экономичный режим работы, в котором энергопотребление снижается на 20 %, а производительность для некоторых нагрузок — всего на 5 %. 
Изображения: Intel Sapphire Rapids предлагают 8 каналов памяти DDR5-4800 (1DPC) и DDR5-4400 (2DPC). 2DPC у Genoa пока что нет. Кроме того, контроллеры поддерживают и модули Optane PMem 300 (Crow Pass), но с учётом того, что производство 3D XPoint прекращено, достаться они могут не всем (впрочем, не всем они и нужны). Ну а маленькая серия Max также включает 64 Гбайт набортной HBM2e-памяти (1,2 Тбайт/с). Остались и отличия в максимальном объёме SGX-анклавов в зависимости от модели CPU. 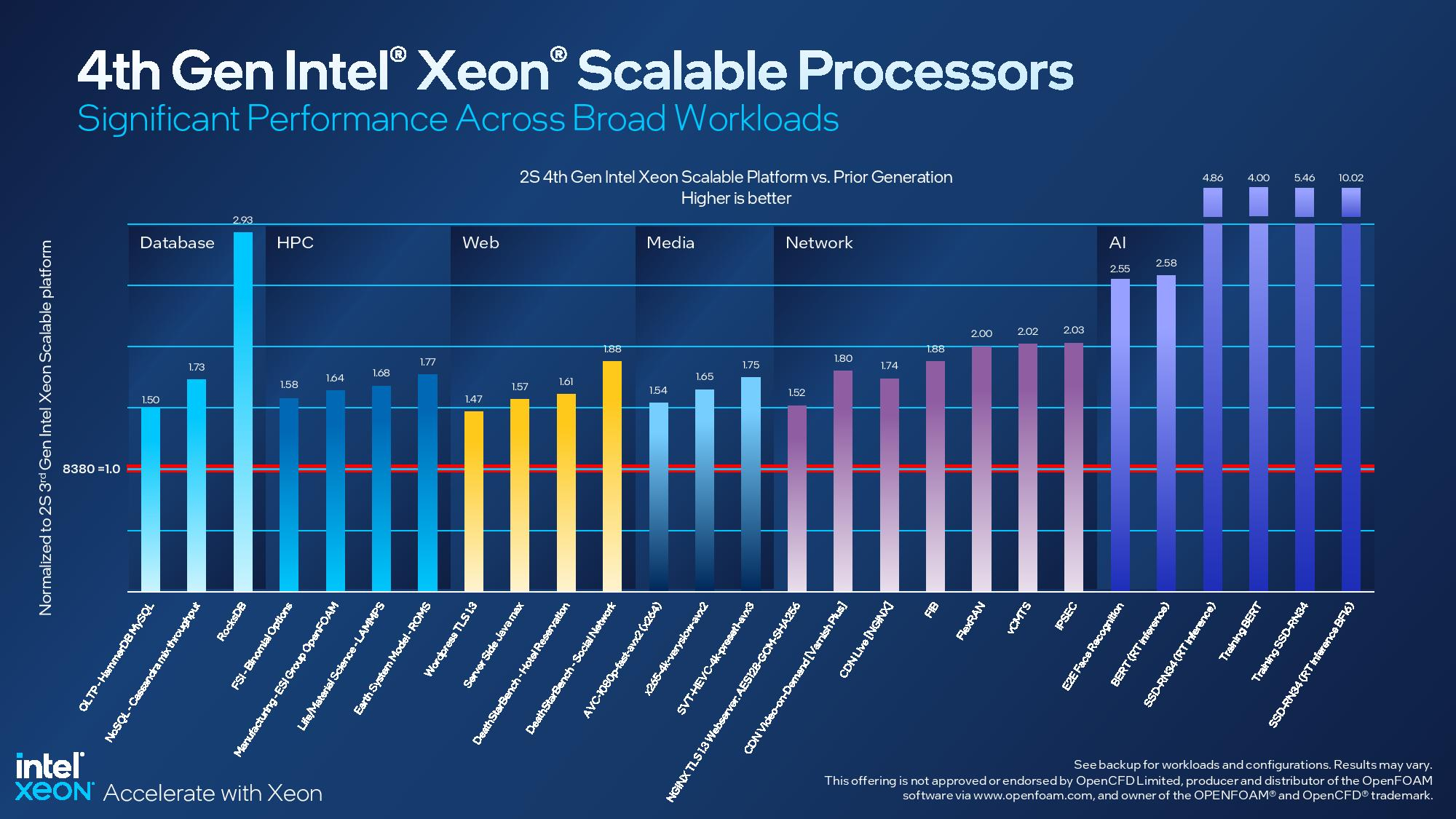 Однако по числу ядер на узел всё равно лидирует Intel. Если AMD поддерживает только 2S-конфигурации, то Intel снова предлагает и 4S, и 8S (а с момента выхода Cooper Lake-SP прошло немало времени) — на процессор доступно до 4 линий UPI 2.0 (16 ГТ/с в сравнении с 11,2 ГТ/с у Ice Lake-SP). В 2S-платформах Sapphire Rapids также формально обгоняет Genoa по числу линий PCIe 5.0, которых тут по 80 шт. на сокет. Формально потому, что в случае Genoa при желании всё же можно получить 160 линий, пожертвовав скоростью шины между CPU, но в односокетном варианте EPYC в любом случае интереснее Xeon. 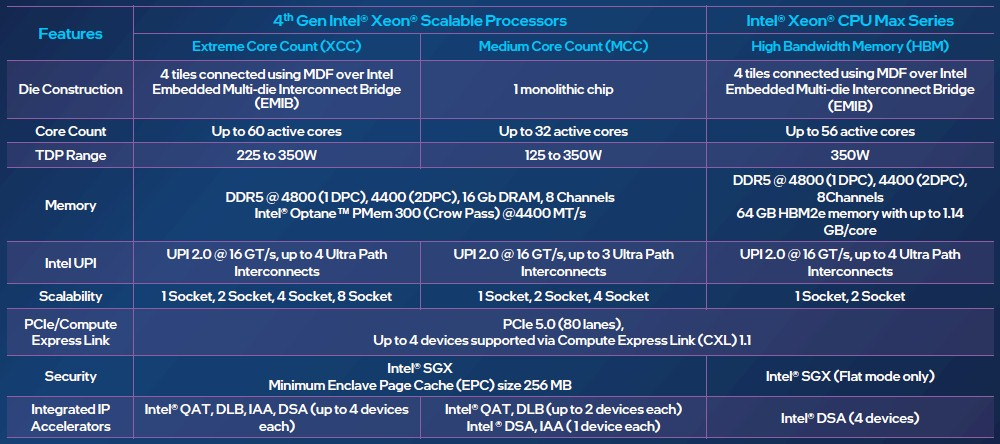 Без нюансов тут не обошлось. Так, при бифуркации до 8 x2 скорость падает до PCIe 4.0. Зато каждый root-комплекс поддерживает CXL 1.1, тогда как у Genoa CXL есть только у половины! Впрочем, поддержка всё равно ограничена 4x CXL-устройствами на CPU. Что ещё более странно, официально заявлена поддержка только устройств Type 1 и Type 2, но не Type 3, хотя последние весьма пригодились бы в ряде конфигураций, где требуется больше относительно недорогой, пусть и несколько более медленной, RAM. 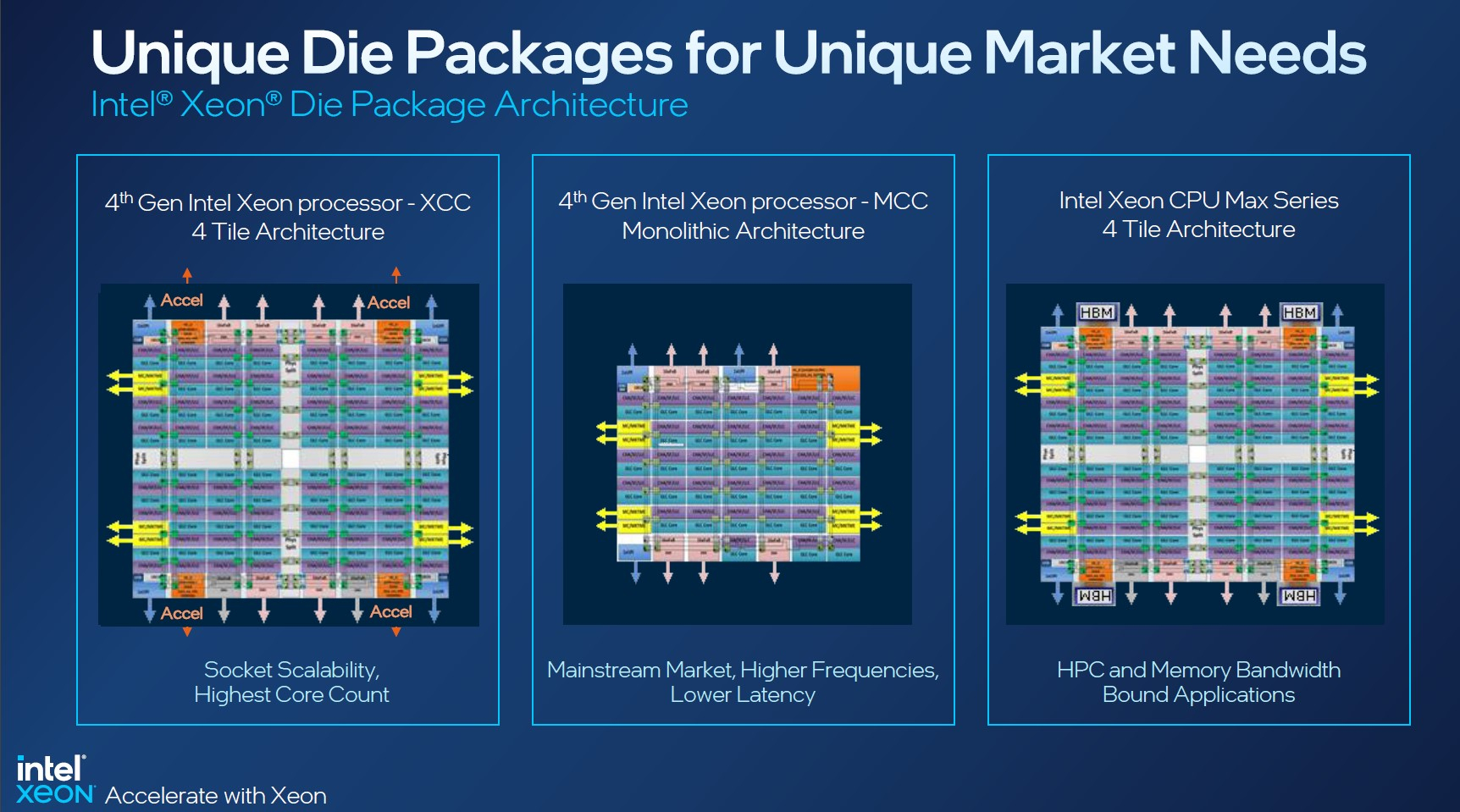 Сохранилось традиционное разделение на серии Platinum (8000), Gold (6000/5000), Silver (4000) и Bronze (3000), к которым теперь добавилась серия Max (9400). Список суффиксов, означающих оптимизацию под те или иные задачи и наличие каких-то особенностей, стал чуть шире: Y (SST-PP 2.0), Q (рассчитаны на работу с СЖО), U (односокетные общего назначения), T (увеличенный жизненный цикл), H (in-memory СУБД, аналитика, виртуализация), N (сетевые решения, в том числе для 5G), облачные P/V/M (IaaS/Paa/медиа), S (СХД и HCI). 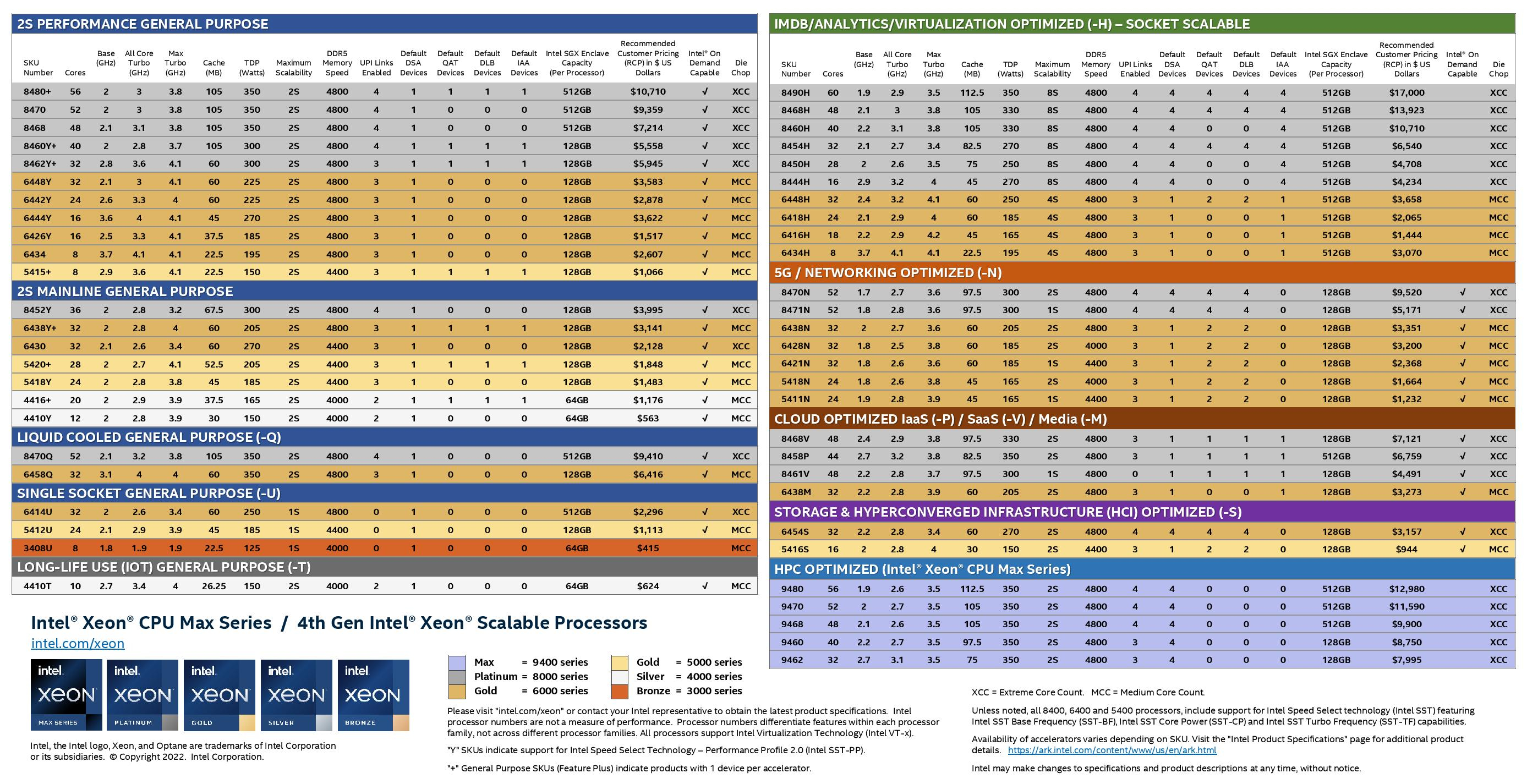 Но некоторые модели также имеют в названии «+». И вот тут начинается самое интересное! Все процессоры получили «традиционную» (в сравнении с Genoa) реализацию AVX-512, включая DL Boost, а также целый новый набор ИИ-инструкций AMX (до 10 раз быстрее обучение и инференс в сравнении с Ice Lake-SP). Есть и всяческие Speed Select, DDIO, TDX, CET и т.д. Но Sapphire Rapids также получили четыре отдельных ускорителя:
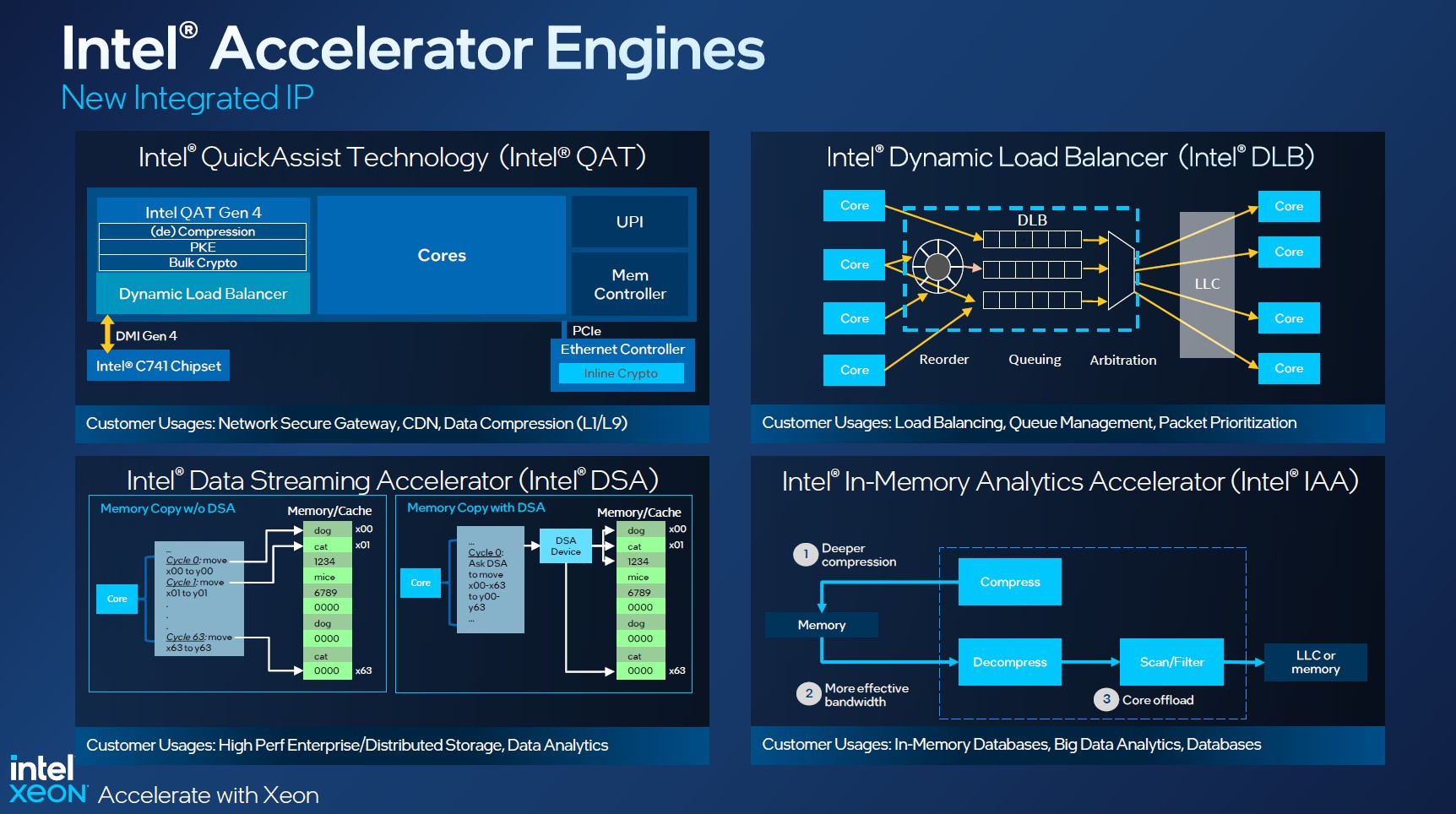 Intel заявляет, что средний прирост производительности Sapphire Rapids в сравнении с Ice Lake-SP составил 1,53 раза. А вот для ряда нагрузок, которые могут задействовать новые ускорители прирост производительности на Вт составляет уже до 2,9 раз! То есть Intel продолжает придерживаться стратегии создания максимально универсальных CPU для различных нагрузок. И действительно, спорить с гибкостью Sapphire Rapids трудно. Но какой ценой это достигается? Т.е. буквально: во сколько это обойдётся заказчику? Ответа пока нет.  Дело в том, что в зависимости от модели отличается число доступных и число активированных ускорителей. Фактически в новом поколении используется два вида кристаллов: XCC, «сшитые» из четырёх отдельных тайлов, и монолитные MCC (до 32 ядер, причём 32-ядерных моделей в серии большинство). У каждого тайла в XCC есть по одному блоку QAT, DSA, DLB и IAA, т.е. суммарно на CPU приходится до четырёх ускорителей каждого типа. В случае MCC может быть по два QAT и DLB и по одному DSA и IAA на процессор. Например, у тех моделей, что помечены «+», активно по одному блоку каждого типа, а минимум один DSA активен есть вообще у всех CPU.  За не активированные по умолчанию ускорители придётся заплатить в рамках программы Intel On Demand (SDSi), причём есть опции как с единовременным платежом за постоянную активацию, так и с оплатой по факту использования (это удобно в случае облаков и платформ по типу HPE Greenlake). Исключением являются H-модели, куда входит и самый дорогой ($17000) 60-ядерный процессор 8490H с полностью разблокированными ускорителями и поддержкой 8S-конфигураций, а также процессоры Max, которым доступно только четыре DSA-блока и 2S-платформы, например, 56-ядерный 9480 ($12980). 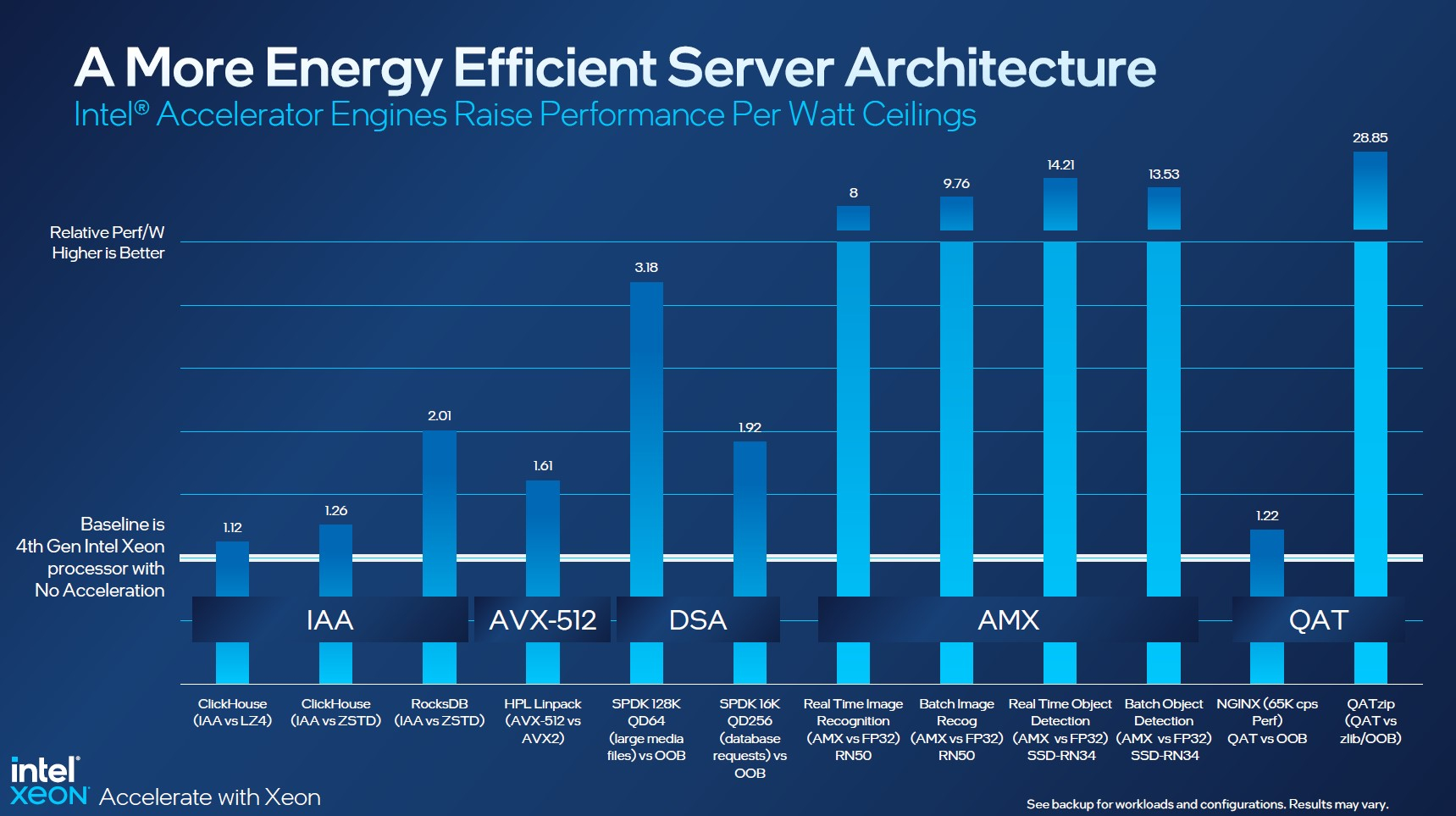 С одной стороны, желание Intel предоставить больше гибкости заказчикам, а заодно чуть увеличить выход годных к продаже процессоров, понятно. С другой — не очень-то и похоже, что CPU без «лишних» ускорителей отдаются с какой-то существенной скидкой. При этом транзисторный бюджет на них всё равно расходуется. Кроме того, есть ещё момент востребованности этих ускорителей и готовности ПО. У Intel есть и опыт ресурсы для помощи разработчикам, но процесс адаптации в любом случае не мгновенен.  Впрочем, у Intel по сравнению с AMD есть и ещё одно важное преимущество — в среднем более высокая доступность процессоров для большинства заказчиков. Так что с Sapphire Rapids может повториться та же история, что с Ice Lake-SP, когда вендоры здесь и сейчас готовы были предложить Intel-платформы.  В целом же, в новом семействе наиболее любопытны Xeon Max, которые, по словам Intel, по сравнению с прошлым поколением в 3,7 раз производительнее в задачах, завязанных на пропускную способность памяти (а это целый пласт HPC-нагрузок), и которые не так уж дороги. Правда, и здесь без приключений не обошлось — несчастный суперкомпьютер Aurora ожидает утомительный апгрейд его 10 тыс. узлов c простых Xeon Sapphire Rapids на Xeon Max — по полчаса на каждый узел.
10.11.2022 [01:55], Игорь Осколков
Intel объединила HBM-версии процессоров Xeon Sapphire Rapids и ускорители Xe HPC Ponte Vecchio под брендом MaxВ преддверии SC22 и за день до официального анонса AMD EPYC Genoa компания Intel поделилась некоторыми подробностями об HBM-версии процессоров Xeon Sapphire Rapids и ускорителях Ponte Vecchio, которые теперь входят в серию Intel Max. 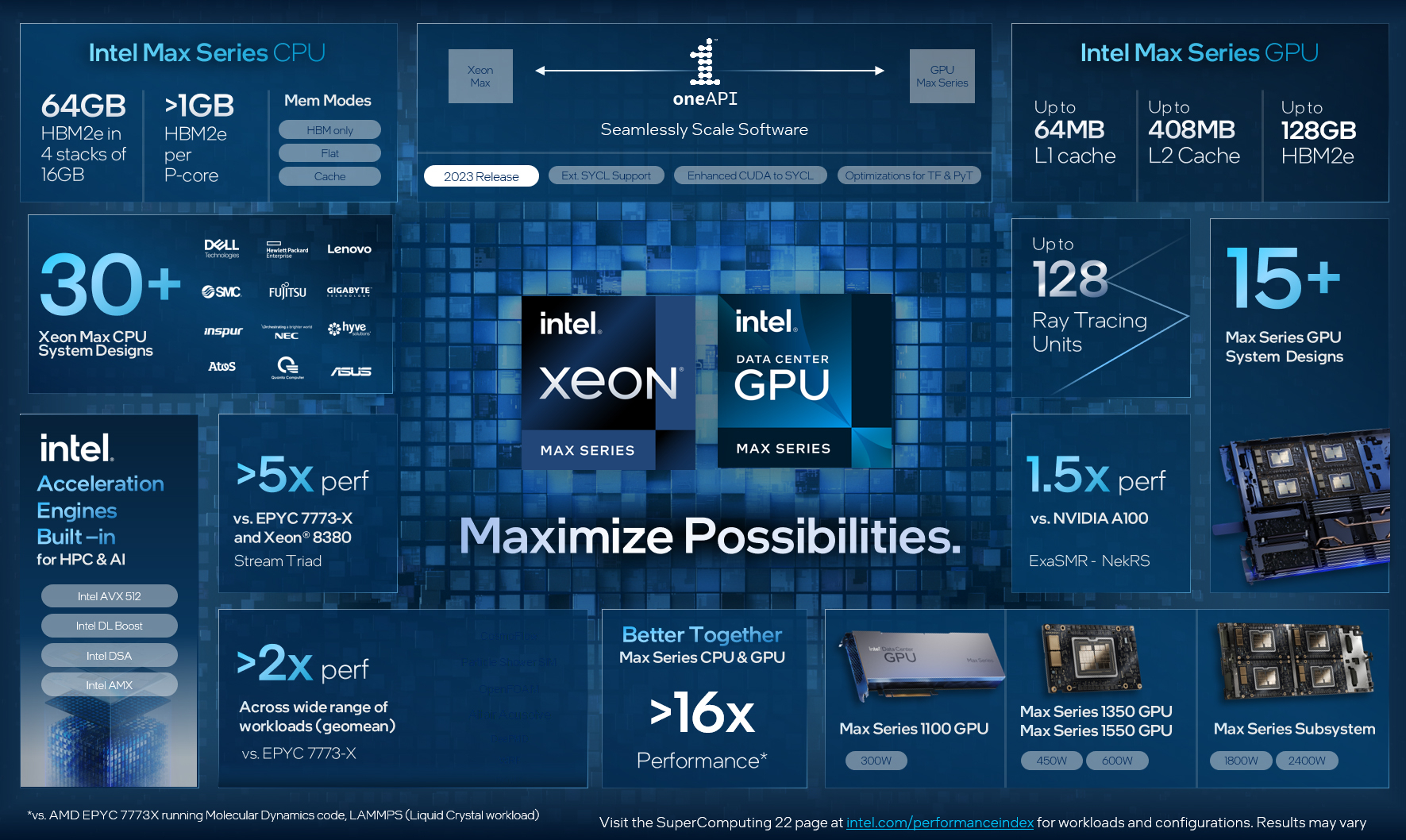
Изображения: Intel Intel Xeon Max предложат до 56 P-ядер, 112,5 Мбайт L3-кеша, 64 Гбайт HBM2e-памяти (четыре стека) с пропускной способностью порядка 1 Тбайт/с, 8 каналов памяти (DDR5-4800 в случае 1DPC, суммарно до 6 Тбайт), а также интерфейсы PCIe 5.0, CXL 1.1, UPI 2.0 и целый ряд различных технологий ускорения для задач HPC и ИИ: AVX-512, DL Boost, AMX, DSA, QAT и т.д. Заявленный уровень TDP составляет 350 Вт.  Первым процессором с набортной HBM-памятью был Arm-чип Fujitsu A64FX (48 ядер, 32 Гбайт HBM2), лёгший в основу суперкомпьютера Fugaku. Intel поднимает планку, давая более 1 Гбайт быстрой памяти на каждое ядро. А поскольку процессор состоит из четырёх отдельных чиплетов, возможно создание четырёх NUMA-доменов с выделенными HBM- и DDR-контроллерами. Но и монолитный режим тоже имеется. А поддержка CXL даёт возможность задействовать RAM-экспандеры. 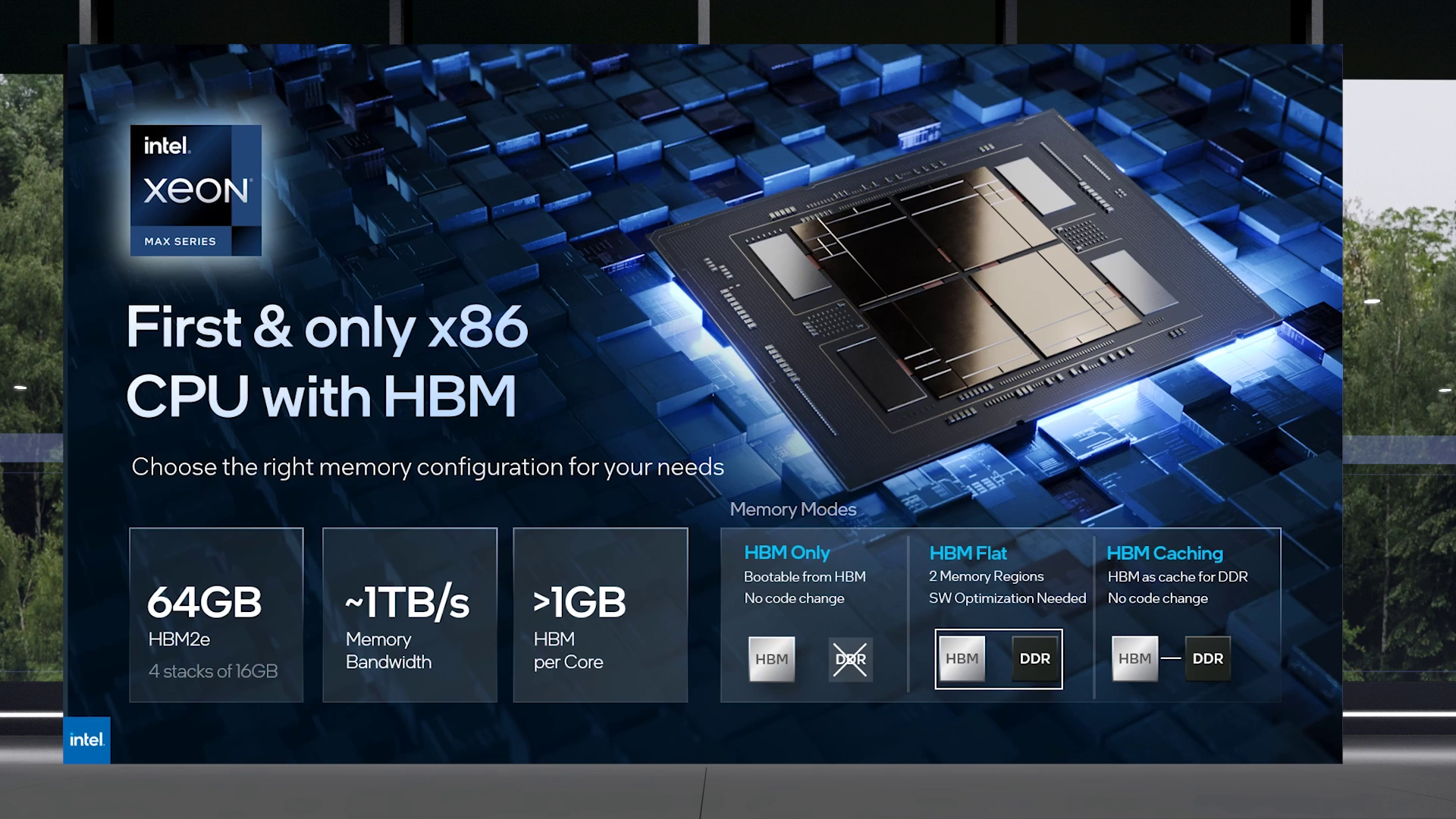 Intel Xeon Max поддерживают 2S-платформы, что суммарно даёт уже 128 Гбайт HBM-памяти, которых вполне хватит для целого ряда задач. Новые процессоры действительно могут обходиться без DIMM. Но есть и два других режима. В первом HBM-память работает в качестве кеша для обычной памяти, и для системы это происходит прозрачно, так что никаких модификаций для ПО (как в случае отсутствия DIMM вообще) не требуется. Во втором режиме HBM и DDR представлены как отдельные пространства, так что тут дорабатывать ПО придётся, зато можно добиться более эффективного использования обоих типов памяти.
В презентации Intel сравнивает новые Xeon Max с AMD EPYC Milan-X – в зависимости от задачи прирост составляет от +20 % до 4,8 раз. Но, во-первых, уже сегодня эти тесты потеряют всякий смысл в связи с презентацией EPYC Genoa (которые, к слову, должны получить AVX-512), а во-вторых, в следующем году AMD обещает представить Genoa-X с 3D V-Cache. Intel же явно не оставляет попытки создать как можно более универсальный процессор.  Что касается Ponte Vecchio, которые теперь называются Max GPU, то практически ничего нового относительно строения и особенностей данных ускорителей Intel не сказала: до 128 ядер Xe (только теперь стало известно об аппаратном ускорении трассировки лучей, что важно для визуализации), 64 Мбайт L1-кеша и аж 408 Мбайт L2-кеша (из них 120 Мбайт приходится на Rambo-кеш в двух стеках), 16 линий Xe Link, 8 HBM2e-контроллеров на 128 Гбайт памяти и пиковая FP64-производительность на уровне 52 Тфлопс. Все эти характеристики относятся к старшей модели Max Series 1550 в OAM-исполнении с TDP в 600 Вт.  Max Series 1350 предложит 112 ядер Xe и 96 Гбайт HBM2e, но и TDP у этой модели составит всего 450 Вт. Для обеих OAM-версий также будут доступны готовые блоки из четырёх ускорителей (по примеру NVIDIA RedStone), объединённых по схеме «каждый с каждым», так что в сумме можно получить 512 Гбайт HBM2e с ПСП в 12,8 Тбайт/с. Ну а самый простой ускоритель в серии называется Max Series 1100. Это 300-Вт PCIe-плата с 56 Xe-ядрами, 48 Гбайт HBM2e и мостиками Xe Link.  Intel утверждает, что ускорители Max до двух раз быстрее NVIDIA A100 в некоторых задачах, но и здесь история повторяется — нет сравнения с более современными H100. Хотя предварительный доступ к этим ускорителям у Intel есть, поскольку именно Sapphire Rapids являются составной частью платформы DGX H100. В целом, Intel прямо говорит, что наибольшей эффективности вычислений позволяет добиться связка CPU и GPU серии Max в сочетании с oneAPI. Всего на базе решений данной серии готовится более 40 продуктов.
Пока что приоритетным для Intel проектом является 2-Эфлопс суперкомпьютер Aurora, для которого пока что создан тестовый кластер Sunspot со 128 узлами, содержащими ускорители Max. Следующим ускорителем Intel станет Rialto Bridge, который появится в 2024 году. Также компания готовит гибридные (XPU) чипы Falcon Shores, сочетающие CPU, ускорители и быструю память. Аналогичный подход применяют AMD и NVIDIA.
19.08.2021 [16:00], Игорь Осколков
Intel представила Xeon Sapphire Rapids: четырёхкристалльная SoC, HBM-память, новые инструкции и ускорителиВ рамках Architecture Day компания Intel рассказала о грядущих серверных процессорах Sapphire Rapids, подтвердив большую часть опубликованной ранее информации и дополнив её некоторыми деталями. Intel позиционирует новинки как решение для более широкого круга задач и рабочих нагрузок, чем прежде, включая и популярные ныне микросервисы, контейнеризацию и виртуализацию. Компания обещает, что CPU будут сбалансированы с точки зрения вычислений, работой с памятью и I/O. Новые процессоры, наконец, получили чиплетную, или тайловую в терминологии Intel, компоновку — в состав SoC входят четыре «ядерных» тайла на техпроцессе Intel 7 (10 нм Enhanced SuperFIN). Каждый тайл объединён с соседом посредством EMIB. Их системные агенты, включающие общий на всех L3-кеш объём до 100+ Мбайт, образуют быструю mesh-сеть с задержкой порядка 4-8 нс в одну сторону. Со стороны процессор будет «казаться» монолитным.  Каждые ядро или поток будут иметь свободный доступ ко всем ресурсам соседних тайлов, включая кеш, память, ускорители и IO-блоки. Потенциально такой подход более выгоден с точки зрения внутреннего обмена данными, чем в случае AMD с общим IO-блоком для всех чиплетов, которых в будущих EPYC будет уже 12. Но как оно будет на самом деле, мы узнаем только в следующем году — выход Sapphire Rapids запланирован на первый квартал 2022-го, а массовое производство будет уже во втором квартале.  Ядра Sapphire Rapids базируются на микроархитектуре Golden Cove, которая стала шире, глубже и «умнее». Она же будет использована в высокопроизводительных ядрах Alder Lake, но в случае серверных процессоров есть некоторые отличия. Например, увеличенный до 2 Мбайт на ядро объём L2-кеша или новый набор инструкций AMX (Advanced Matrix Extension). Последний расширяет ИИ-функциональность CPU и позволяет проводить MAC-операции над матрицами, что характерно для такого рода нагрузок.  Для AMX заведено восемь выделенных 2D-регистров объёмом по 1 Кбайт каждый (шестнадцать 64-байт строк). Отдельный аппаратный блок выполняет MAC-операции над тремя регистрами, причём делаться это может параллельно с исполнением других инструкций в остальной части ядра. Настройкой параметров и содержимого регистров, а также перемещением данных занимается ОС. Пока что в процессорах представлен только MAC-блок, но в будущем могут появиться блоки и для других, более сложных операций. 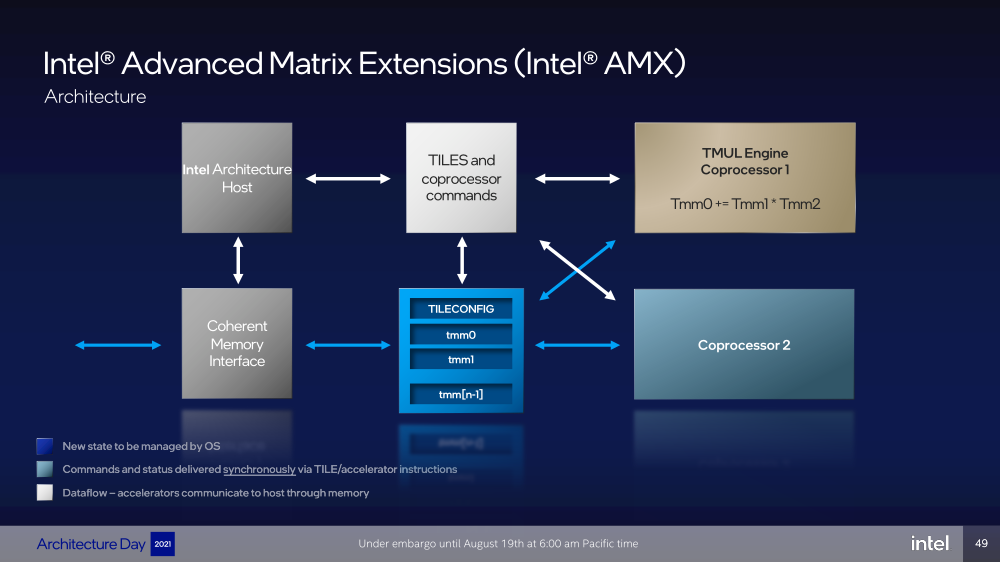 В пике производительность AMX на INT8 составляет 2048 операций на цикл на ядро, что в восемь раз больше, чем при использовании традиционных инструкций AVX-512 (на двух FMA-портах). На BF16 производительность AMX вдвое ниже, но это всё равно существенный прирост по сравнению с прошлым поколением Xeon — Intel всё так же пытается создать универсальные ядра, которые справлялись бы не только с инференсом, но и с обучением ИИ-моделей. Тем не менее, компания говорит, что возможности AMX в CPU будут дополнять GPU, а не напрямую конкурировать с ними.  К слову, именно Sapphire Rapids должен, наконец, сделать BF16 более массовым, поскольку Cooper Lake, где поддержка этого формата данных впервые появилась в CPU Intel, имеет довольно узкую нишу применения. Из прочих архитектурных обновлений можно отметить поддержку FP16 для AVX-512, инструкции для быстрого сложения (FADD) и более эффективного управления данными в иерархии кешей (CLDEMOTE), целый ряд новых инструкций и прерываний для работы с памятью и TLB для виртуальных машин (ВМ), расширенную телеметрию с микросекундными отсчётами и так далее.  Последние пункты, в целом, нужны для более эффективного и интеллектуального управления ресурсами и QoS для процессов, контейнеров и ВМ — все они так или иначе снижают накладные расходы. Ещё больше ускоряют работу выделенные акселераторы. Пока упомянуты только два. Первый, DSA (Data Streaming Accelerator), ускоряет перемещение и передачу данных как в рамках одного хоста, так и между несколькими хостами. Это полезно при работе с памятью, хранилищем, сетевым трафиком и виртуализацией. 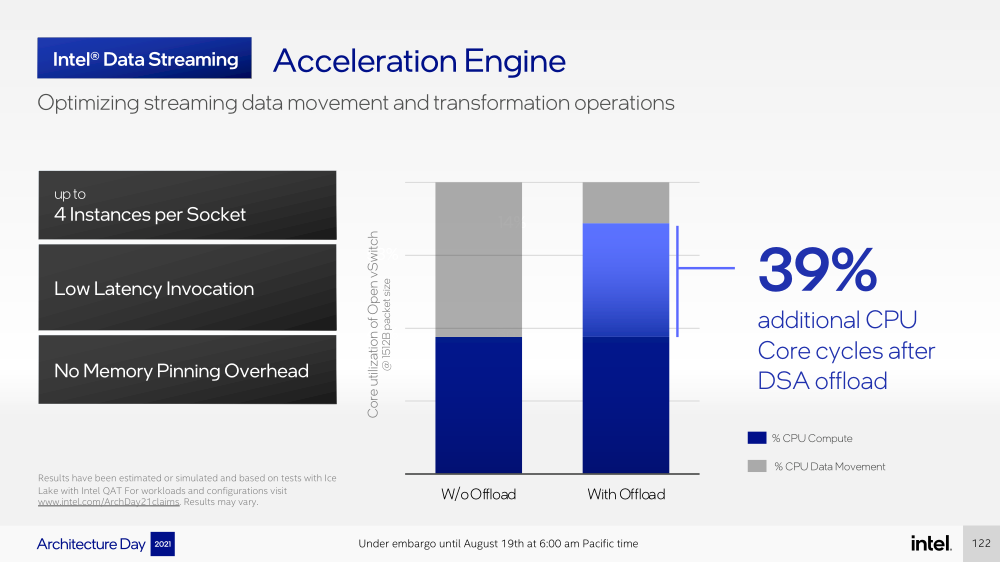 Второй упомянутый ускоритель — это движок QAT (Quick Assist Engine), на который можно возложить операции или сразу цепочки операций (де-)компрессии (до 160 Гбит/с в обе стороны одновременно), хеширования и шифрования (до 400 Гбитс/с) в популярных алгоритмах: AES GCM/XTS, ChaChaPoly, DH, ECC и т.д. Теперь блок QAT стал частью самого процессора, тогда как прежде он был доступен в составе некоторых чипсетов или в виде отдельной карты расширения. Это позволило снизить задержки и увеличить производительность блока. 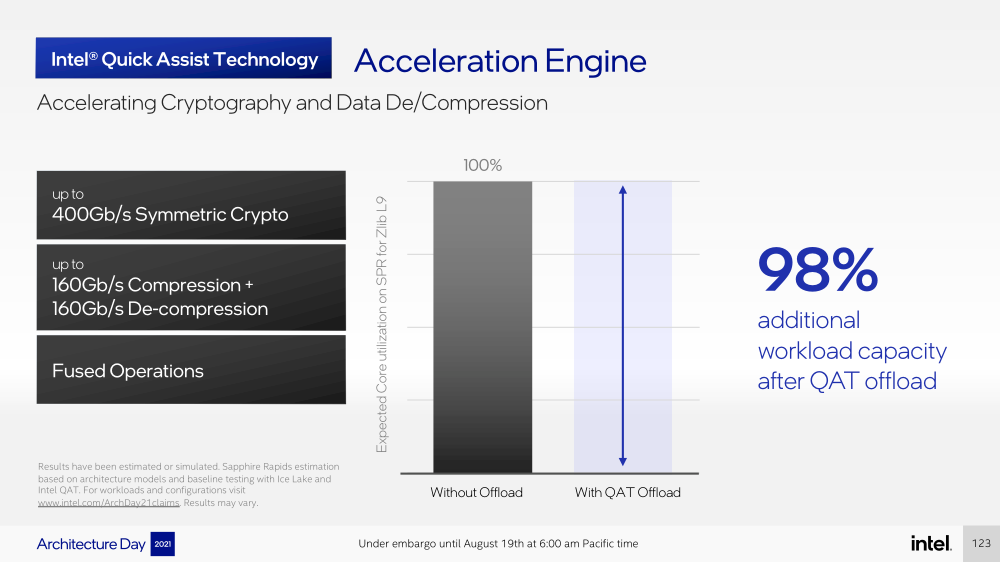 Кроме того, QAT можно будет задействовать, например, для виртуализации или Intel Accelerator Interfacing Architecture (AiA). AiA — это ещё один новый набор инструкций, предназначенный для более эффективной работы с интегрированными и дискретными ускорителями. AiA помогает с управлением, синхронизацией и сигнализацией, что опять таки позволит снизить часть накладных расходов при взаимодействии с ускорителями из пространства пользователя. 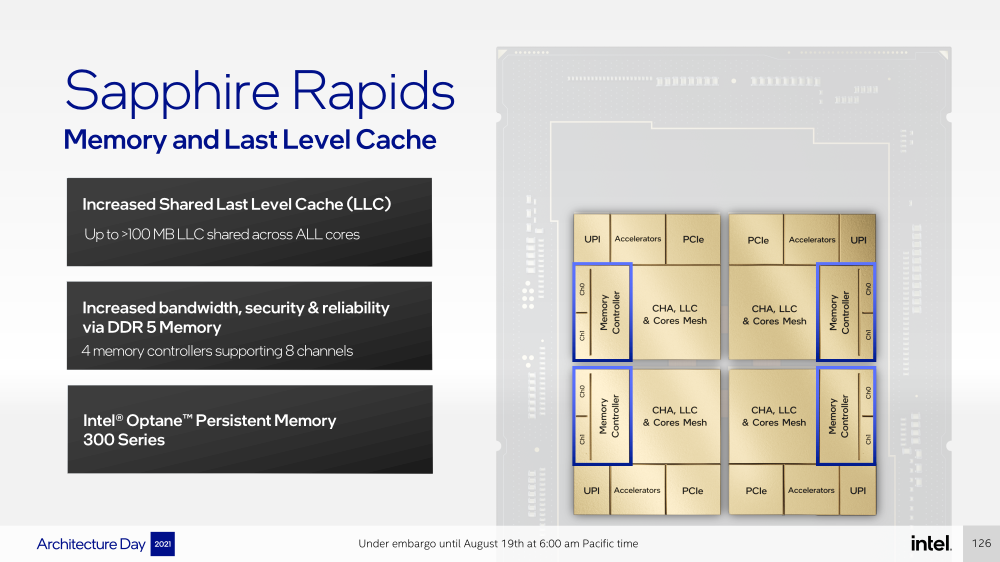 Подсистема памяти включает четыре двухканальных контроллера DDR5, по одному на каждый тайл. Надо полагать, что будут доступные четыре же NUMA-домена. Больше деталей, если не считать упомянутой поддержки следующего поколения Intel Optane PMem 300 (Crow Pass), предоставлено не было. Зато было официально подтверждено наличие моделей с набортной HBM, тоже по одному модулю на тайл. HBM может использоваться как в качестве кеша для DRAM, так и независимо. В некоторых случаях можно будет обойтись вообще без DRAM. 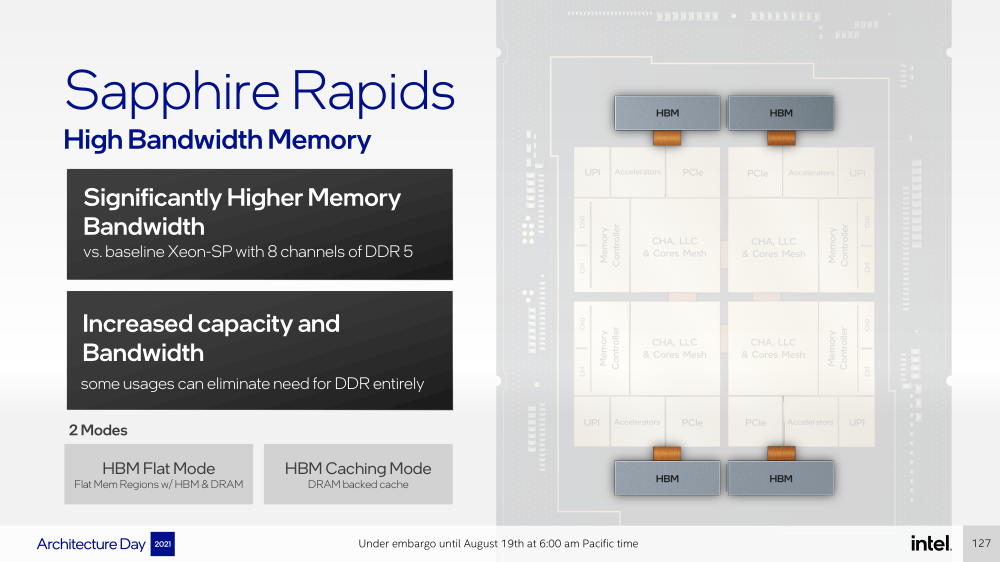 Про PCIe 5.0 и CXL 1.1 (CXL.io, CXL.cache, CXL.memory) добавить нечего, хотя в рамках другого доклада Intel ясно дала понять, что делает ставку на CXL в качестве интерконнекта не только внутри одного узла, но и в перспективе на уровне стойки. Для объединения CPU (бесшовно вплоть до 8S) всё так же будет использоваться шина UPI, но уже второго поколения (16 ГТ/с на линию) — по 24 линии на каждый тайл. 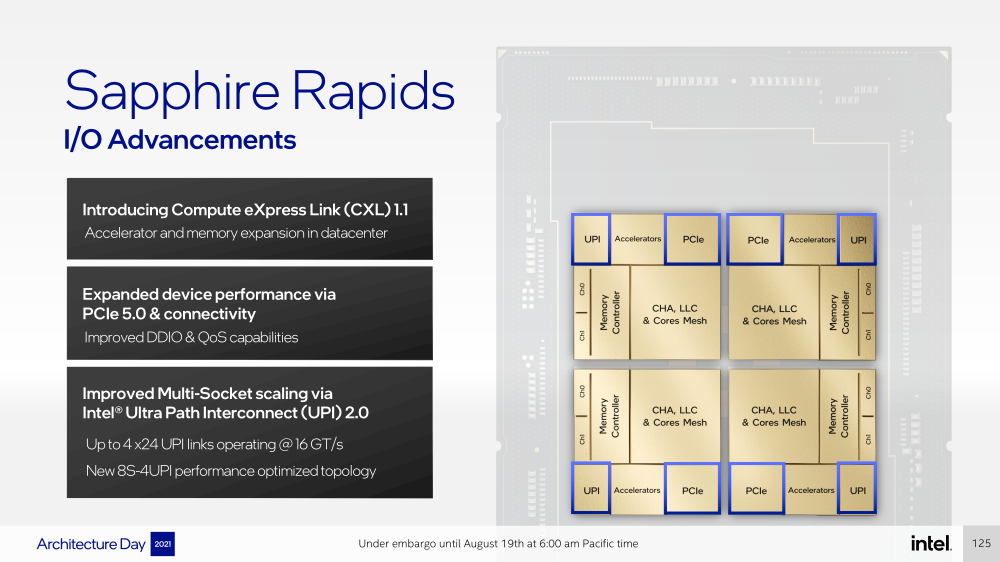 Конкретно для Sapphire Rapids Intel пока не приводит точные данные о росте IPC в сравнении с Ice Lake-SP, ограничиваясь лишь отдельными цифрами в некоторых задачах и областях. Также не был указан и ряд других важных параметров. Однако AMD EPYC Genoa, если верить последним утечкам, даже по чисто количественным характеристикам заметно опережает Sapphire Rapids. |
|


